day 25 portrait mode for photos
Portrait Photo
create portrait photo
import cv2
import numpy as np
import os
import tarfile
import urllib
from matplotlib import pyplot as plt
import tensorflow as tf
import os
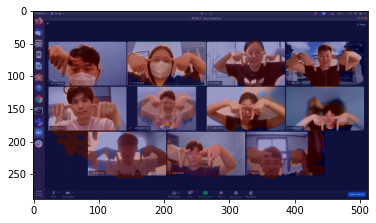
img_path = os.getenv('HOME')+'/aiffel/human_segmentation/images/my_image1.png' # 본인이 선택한 이미지의 경로에 맞게 바꿔 주세요.
img_orig = cv2.imread(img_path)
print (img_orig.shape)
(304, 392, 3)
class DeepLabModel(object):
INPUT_TENSOR_NAME = 'ImageTensor:0'
output_TENSOR_NAME = 'SemanticPredictions:0'
INPUT_SIZE = 513
FROZEN_GRAPH_NAME = 'frozen_inference_graph'
# __init__()에서 모델 구조를 직접 구현하는 대신, tar file에서 읽어들인 그래프구조 graph_def를
# tf.compat.v1.import_graph_def를 통해 불러들여 활용하게 됩니다.
def __init__(self, tarball_path):
self.graph = tf.Graph()
graph_def = None
tar_file = tarfile.open(tarball_path)
for tar_info in tar_file.getmembers():
if self.FROZEN_GRAPH_NAME in os.path.basename(tar_info.name):
file_handle = tar_file.extractfile(tar_info)
graph_def = tf.compat.v1.GraphDef.FromString(file_handle.read())
break
tar_file.close()
with self.graph.as_default():
tf.compat.v1.import_graph_def(graph_def, name='')
self.sess = tf.compat.v1.Session(graph=self.graph)
# 이미지를 전처리하여 Tensorflow 입력으로 사용 가능한 shape의 Numpy Array로 변환합니다.
def preprocess(self, img_orig):
height, width = img_orig.shape[:2]
resize_ratio = 1.0 * self.INPUT_SIZE / max(width, height)
target_size = (int(resize_ratio * width), int(resize_ratio * height))
resized_image = cv2.resize(img_orig, target_size)
resized_rgb = cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB)
img_input = resized_rgb
return img_input
def run(self, image):
img_input = self.preprocess(image)
# Tensorflow V1에서는 model(input) 방식이 아니라 sess.run(feed_dict={input...}) 방식을 활용합니다.
batch_seg_map = self.sess.run(
self./assets/images/aiffel-post-47/output_TENSOR_NAME,
feed_dict={self.INPUT_TENSOR_NAME: [img_input]})
seg_map = batch_seg_map[0]
return cv2.cvtColor(img_input, cv2.COLOR_RGB2BGR), seg_map
# define model and download & load pretrained weight
_DOWNLOAD_URL_PREFIX = 'http://download.tensorflow.org/models/'
model_dir = os.getenv('HOME')+'/aiffel/human_segmentation/models'
tf.io.gfile.makedirs(model_dir)
print ('temp directory:', model_dir)
download_path = os.path.join(model_dir, 'deeplab_model.tar.gz')
if not os.path.exists(download_path):
urllib.request.urlretrieve(_DOWNLOAD_URL_PREFIX + 'deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz',
download_path)
MODEL = DeepLabModel(download_path)
print('model loaded successfully!')
temp directory: /aiffel/aiffel/human_segmentation/models
model loaded successfully!
img_resized, seg_map = MODEL.run(img_orig)
print (img_orig.shape, img_resized.shape, seg_map.max())
(304, 392, 3) (397, 513, 3) 15
LABEL_NAMES = [
'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'
]
len(LABEL_NAMES)
21
img_show = img_resized.copy()
seg_map = np.where(seg_map == 15, 15, 0) # 예측 중 사람만 추출
img_mask = seg_map * (255/seg_map.max()) # 255 normalization
img_mask = img_mask.astype(np.uint8)
color_mask = cv2.applyColorMap(img_mask, cv2.COLORMAP_JET)
img_show = cv2.addWeighted(img_show, 0.6, color_mask, 0.35, 0.0)
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()

img_mask_up = cv2.resize(img_mask, img_orig.shape[:2][::-1], interpolation=cv2.INTER_LINEAR)
_, img_mask_up = cv2.threshold(img_mask_up, 128, 255, cv2.THRESH_BINARY)
ax = plt.subplot(1,2,1)
plt.imshow(img_mask_up, cmap=plt.cm.binary_r)
ax.set_title('Original Size Mask')
ax = plt.subplot(1,2,2)
plt.imshow(img_mask, cmap=plt.cm.binary_r)
ax.set_title('DeepLab Model Mask')
plt.show()

img_orig_blur = cv2.blur(img_orig, (13,13)) #(13,13)은 blurring kernel size를 뜻합니다.
plt.imshow(cv2.cvtColor(img_orig_blur, cv2.COLOR_BGR2RGB))
plt.show()

img_mask_color = cv2.cvtColor(img_mask_up, cv2.COLOR_GRAY2BGR)
img_bg_mask = cv2.bitwise_not(img_mask_color)
img_bg_blur = cv2.bitwise_and(img_orig_blur, img_bg_mask)
plt.imshow(cv2.cvtColor(img_bg_blur, cv2.COLOR_BGR2RGB))
plt.show()

img_concat = np.where(img_mask_color==255, img_orig, img_bg_blur)
plt.imshow(cv2.cvtColor(img_concat, cv2.COLOR_BGR2RGB))
plt.show()

self project
import copy
LABEL_NAMES = [
'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'
]
len(LABEL_NAMES)
for i in range(1,7):
if i < 4:
img_path = os.getenv('HOME')+'/aiffel/human_segmentation/images/my_image'+str(i)+'.png' # 본인이 선택한 이미지의 경로에 맞게 바꿔 주세요.
else:
img_path = os.getenv('HOME')+'/aiffel/human_segmentation/images/my_image'+str(i)+'.jpg' # 본인이 선택한 이미지의 경로에 맞게 바꿔 주세요.
print("This is my_image" + str(i))
img_orig = cv2.imread(img_path)
MODEL = DeepLabModel(download_path)
print('model loaded successfully!')
img_resized, seg_map = MODEL.run(img_orig)
print (img_orig.shape, img_resized.shape, seg_map.max())
img_show = img_resized.copy()
seg_map = np.where(seg_map == 15, 15, 0) # 예측 중 사람만 추출
img_mask = seg_map * (255/seg_map.max()) # 255 normalization
img_mask = img_mask.astype(np.uint8)
color_mask = cv2.applyColorMap(img_mask, cv2.COLORMAP_JET)
img_show = cv2.addWeighted(img_show, 0.6, color_mask, 0.35, 0.0)
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()
img_mask_up = cv2.resize(img_mask, img_orig.shape[:2][::-1], interpolation=cv2.INTER_LINEAR)
_, img_mask_up = cv2.threshold(img_mask_up, 128, 255, cv2.THRESH_BINARY)
ax = plt.subplot(1,2,1)
plt.imshow(img_mask_up, cmap=plt.cm.binary_r)
ax.set_title('Original Size Mask')
ax = plt.subplot(1,2,2)
plt.imshow(img_mask, cmap=plt.cm.binary_r)
ax.set_title('DeepLab Model Mask')
plt.show()
img_orig_blur = cv2.blur(img_orig, (13,13)) #(13,13)은 blurring kernel size를 뜻합니다.
plt.imshow(cv2.cvtColor(img_orig_blur, cv2.COLOR_BGR2RGB))
plt.show()
img_mask_color = cv2.cvtColor(img_mask_up, cv2.COLOR_GRAY2BGR)
img_bg_mask = cv2.bitwise_not(img_mask_color)
img_bg_blur = cv2.bitwise_and(img_orig_blur, img_bg_mask)
plt.imshow(cv2.cvtColor(img_bg_blur, cv2.COLOR_BGR2RGB))
plt.show()
img_concat = np.where(img_mask_color==255, img_orig, img_bg_blur)
plt.imshow(cv2.cvtColor(img_concat, cv2.COLOR_BGR2RGB))
plt.show()
This is my_image1
model loaded successfully!
(304, 392, 3) (397, 513, 3) 15





This is my_image2
model loaded successfully!
(223, 375, 3) (305, 513, 3) 15





This is my_image3
model loaded successfully!
(450, 800, 3) (288, 513, 3) 20





This is my_image4
model loaded successfully!
(603, 960, 3) (322, 513, 3) 15





This is my_image5
model loaded successfully!
(720, 1280, 3) (288, 513, 3) 20
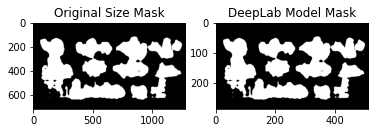
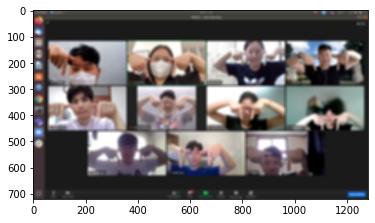

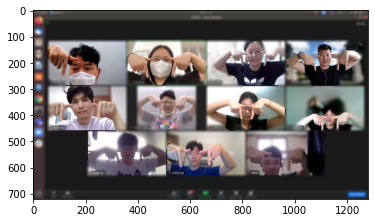
This is my_image6
model loaded successfully!
(1280, 959, 3) (513, 384, 3) 15





위 사진들의 문제점들
in image1, there is too much noticeable border 이미지의 경계가 불 명확하다
in image2, there is also too much noticeable border 이미지의 경계가 불 명확하다
in image3, there is a shirt in the background that is not blurred 이미지의 셔츠가 포함되어 있다
in image4, it captured everyone in the shot instead of just me 이미지의 모든 4 사람들이 전부 포함되어있다
in image5, it captured non human objects as humans. 이미지의 검은색 백그라운드도 사람으로 포함이 되어있다
in image6, it captured people in the background. 뒷 배경의 사람들도 포함이 되어있다
Conclusion
대체로 잘 분류하는 것 같지만, 문제가 좀 있습니다. 마지막 사진의 경우에는 옆에 있는 사람하고 같이 나왔어요.
세그멘테이션 그 자체의 한계일수도 있습니다.
세그멘테이션의 한계
Semantic segmentation의 부정확성이 여러가지 문제를 발생시키는 주요 원인입니다. 피사계심도를 이용한 보케(아웃포커싱) 효과는 말 그대로 심도를 표현하기 때문에 초점이 잡힌 거리를 광학적으로 아주 섬세하게 구별(segmentation) 하지만 이를 따라한 semantic segmentation 모듈은 정확도가 1.00 이 되지 않는 한 완벽히 구현하기는 힘듭니다.
피사계 심도 이해하기
우선 피사계심도의 개념부터 명확히 이해해 봅시다.
참고자료 : https://ggyul.tistory.com/12
3D Depth Camera 활용하기
카메라 2개를 통해 생성한 3d 영상으로 인물모드를 더 정확하게 만들 수 있을까요? 우리는 카메라 1대가 찍은 영상에서 semantic segmentation을 시도하였고, 그 결과가 정확하지 않았습니다. 요즘 스마트폰의 카메라는 렌즈가 2개 달려있지요? 왜 굳이 그렇게까지 하는지 아래 링크를 보면서 이해해 봅시다.
참고자료 : https://m.blog.naver.com/panoptics/221336152952
깊이 영상(Depth image) 활용하기
하지만 꼭 카메라가 2개여야 할까요? 아래 이미지는 Struct2Depth 라는 기법을 소개한 Google Brain의 논문에 있는 이미지입니다. 세번째 컬럼이 보다 명확하게 depth에 따른 물체인식을 보여 주는데, 이것은 LiDAR가 없이도 아주 정확한 segmentation을 동반한 depth sensor가 가능함을 보여줍니다.
참고자료 : https://towardsdatascience.com/depth-prediction-autonomous-driving-18d05ff25dd6 참고자료 : https://sites.google.com/view/struct2depth
IR(적외선)을 활용한 사례
구글 pixel4에 IR 카메라가 달려있는데, 이를 통해 보다 멋진 3d depth sensing이 가능하다는군요.
참고자료 : https://ai.googleblog.com/2020/04/udepth-real-time-3d-depth-sensing-on.html
Leave a comment